SQL Data Examiner comparison options
This article describes SQL Data Examiner 2023. However, the options described here are available with some limitations in SQL Data Examiner 2012 and later versions.
The options can be configured in the New Data Comparison wizard (New → Next → Options → Comparison Options) for a new comparison:
and in the Edit Project window (Edit Project → Options tab) for an existing comparison:
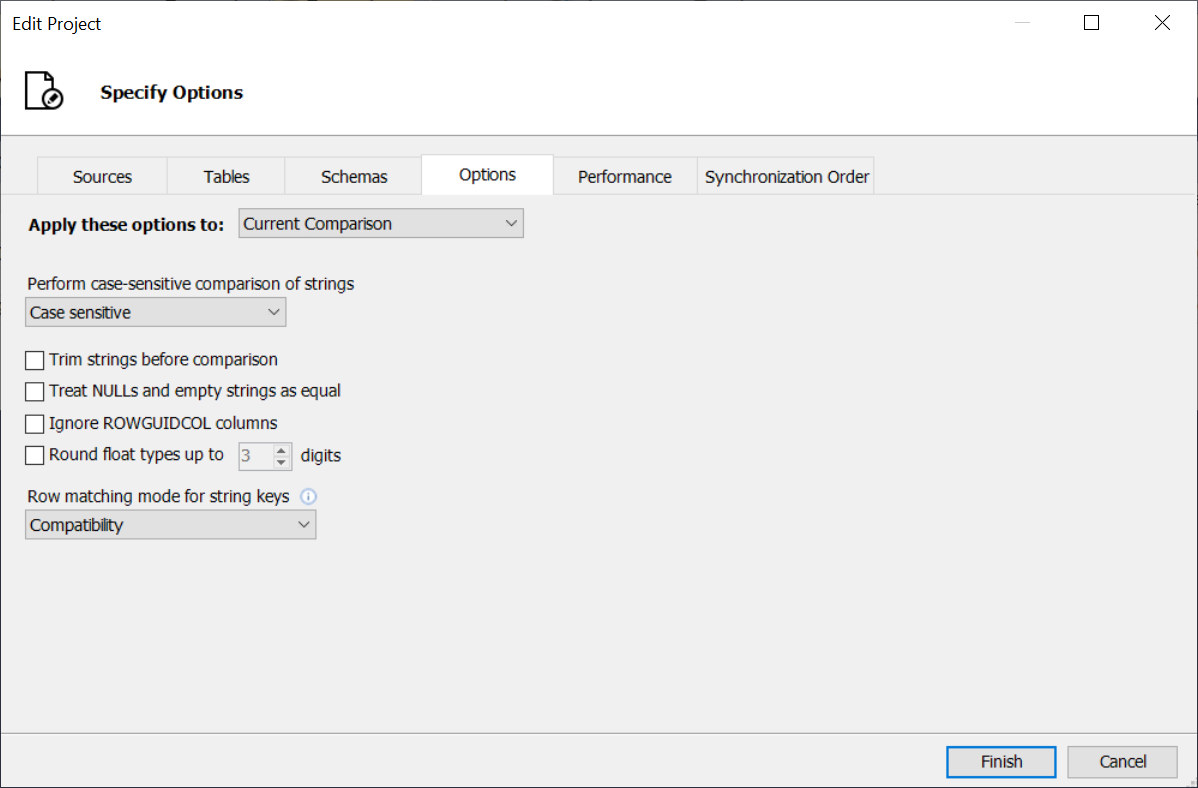
"Apply these options to" defines whether the options will be applicable only to the Current Comparison or to the Current and All New Comparisons. If the second one is chosen, the specified options will also be used in all comparisons made after the current one.
Perform case-sensitive comparison of strings
The option defines whether the comparison will be case-sensitive or not. The Use column collation rules setting defines that the case sensitivity is determined by the corresponding collation - CS (case-sensitive).
If there is a difference between collations in source and target databases, this situation is handled as follows: if the collation of at least one of the two databases is case-insensitive, the comparison is also case-insensitive.
Trim strings before comparison
This option enables trimming spaces at the beginning or end of a value. This is necessary when a database uses fixed-size data types and always returns the defined amount of chars. E.g. if a field has a char(8) type and contains 7 chars, a space will be added automatically. When "Trim strings before comparison" is enabled, the space will be trimmed before comparison and won't affect its result. By default, the option is disabled.
Treat NULLs and empty strings as equal
If the option is enabled, NULL values and empty strings will be considered as equal, otherwise, as different. By default, the option is disabled.
Ignore ROWGUIDCOL columns
The ROWGUIDCOL columns are used for SQL Server replication and in most cases can be ignored.
Round float types
Rounds numeric values retrieved from source and target databases to the specified number of decimal places. These values are compared, displayed in the program and transferred to the target database (or exported) already rounded.
This is useful when comparing floating point data stored in the source database and the target database with data types that differ in precision (for example, double and float).
Floating point data types are not meant to store values exactly, they are meant to store a large range of values with a certain precision. For example, the closest IEEE 754 double value that represents decimal 0.1 is 0.1000000000000000055511151231257827021181583404541015625. As a consequence, values that are the same may literally be different due to the nature of floating point data types.
Row matching mode for string keys
The option affects comparisons where string comparison keys are used. The comparison algorithm requires sorting data by comparison key. The sorting can be done either by SQL Data Examiner (Compatibility mode, default) or by the database server using the ORDER BY construction (Performance mode). If string comparison keys are used, in cross-platform comparisons or when database schemas are different, the results of sorting in Performance mode may differ for the source and target databases. Finally, during comparison the data can be wrongly marked as "Only in Source" or "Only in Target". When the Compatibility mode is chosen, the values are sorted in the same way in both the source and target databases which ensures correct comparison results.